VOSK es un kit de herramientas de reconocimiento de voz:

- Funciona sin conexión, incluso en dispositivos ligeros como Raspberry Pi, Android e iOS además de poderse instalar en Linux.
- Instala con un simple pip3 install vosk.
- Proporciona una API de transmisión para la mejor experiencia de usuario.
- Permite una rápida reconfiguración del vocabulario para obtener la mejor precisión.
- Admite la identificación del altavoz además del simple reconocimiento del habla.
luego:

Yo le voy a poner un archivo wav de 16000 Hz mono, uno que yo hice (puede hacerlo con Audacity):
test_es.wav



Desglosemos el comando:
vosk-transcriber -l es -i test_es.wav -o transcription.txt

para ver la ayuda poner:
ejemplo el comando:
muestra todos los modelos disponibles:



pero mi pobre ordenador de 4 GB de Memoria RAM y 2.2 GHz de velocidad se colgó.

Dios les bendiga
CONSULTAS:
Herramienta de reconocimiento de voz Vosk
https://alphacephei.com/vosk/
Pip install not working #66
https://github.com/alphacep/vosk-api/issues/66
https://github.com/alphacep/vosk-api/issues/66#issuecomment-1294580890
vosk-transcriber -l cn -i sample.ogg
Automatic Speech Recognition with Vosk
https://medium.com/@johnidouglasmarangon/automatic-speech-recognition-with-vosk-828569219f2b
vosk-transcriber --list-model
vosk-transcriber -n vosk-model-small-pt-0.3 -i audio_pt_br.mp3 -o transcription.txt

VOSK
- Admite más de 20 idiomas y dialectos.- Funciona sin conexión, incluso en dispositivos ligeros como Raspberry Pi, Android e iOS además de poderse instalar en Linux.
- Instala con un simple pip3 install vosk.
- Proporciona una API de transmisión para la mejor experiencia de usuario.
- Permite una rápida reconfiguración del vocabulario para obtener la mejor precisión.
- Admite la identificación del altavoz además del simple reconocimiento del habla.
Instalación en Linux
El siguiente tutorial está hecho en MX Linux 21 de 64 bit (VOSK no funciona en 32 bit)
Instalar la dependencia:
Instalar la dependencia:
sudo apt install python3-pip
luego:
pip3 install vosk

El archivo de audio
Yo le voy a poner un archivo wav de 16000 Hz mono, uno que yo hice (puede hacerlo con Audacity):
test_es.wav

pero he visto que también le ponen mp3. Usted puede grabarlo con Audacity en su ordenador con un micrófono, o en su celular y luego pasarlo a su ordenador, con tal que sea bien nítido y bien vocalizado
Comando de transcripción de voz a texto
Con ese ejemplo poner en una terminal en donde esté el archivo:vosk-transcriber -l es -i test_es.wav -o transcription.txty la transcripción me quedó bien:
esa es la letra de la siguiente alabanza:
Explicación del comando:
El comando utiliza el programa "vosk-transcriber" que es parte del proyecto Vosk, motor de reconocimiento de voz en código abierto que permite la transcripción de audio a texto en varios idiomas.Desglosemos el comando:
vosk-transcriber -l es -i test_es.wav -o transcription.txt
- "vosk-transcriber": Este es el programa que realiza la transcripción de voz a texto utilizando el motor Vosk.
- "-l es": Este es el argumento selector y código del idioma, en este caso, el español. Indica que el programa debe usar el modelo de reconocimiento de voz para el idioma español:
- "-i test_es.wav": La opción "-i" especifica el archivo de entrada. En este caso, "test_es.wav" es el archivo de audio que se quiere transcribir (si usted ponga un nombre que tenga espacios debe encerrarlo en comillas, ejemplo "mi voz.wav" o "mi prueba.mp3").
- "-o transcription.txt": La opción "-o" especifica el archivo de salida. "transcription.txt" es el archivo donde se guardará la transcripción de texto generada a partir del audio.
En resumen, el comando está configurado para transcribir el contenido del archivo de audio "test_es.wav" en español y guardar la transcripción resultante en el archivo "transcription.txt".
Si necesitas más información sobre el uso de Vosk o el comando "vosk-transcriber", puedes consultar la documentación oficial en el sitio web de Vosk [Vosk Speech Recognition Toolkit].
para ver la ayuda poner:
vosk-transcriber --help
ejemplo el comando:
vosk-transcriber --list-modelmuestra todos los modelos disponibles:
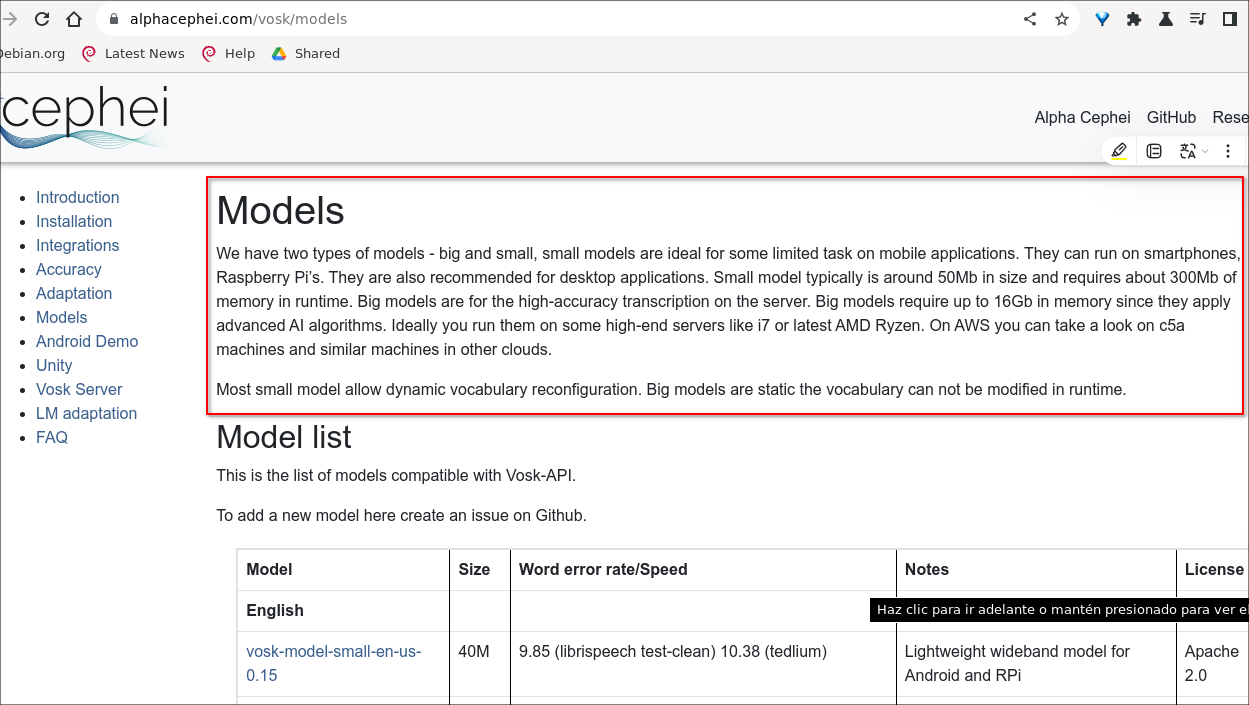
La voz más precisa de tamaño más grande dice allí en la página que es para ordenadores de más de 16 GB de Memoria RAM y que la recomiendan para el uso en servidores:
Modelos de voces:
https://alphacephei.com/vosk/models
https://alphacephei.com/vosk/models

la traducción:
"Tenemos dos tipos de modelos: grandes y pequeños; los modelos pequeños son ideales para algunas tareas limitadas en aplicaciones móviles. Pueden ejecutarse en teléfonos inteligentes, Raspberry Pi. También se recomiendan para aplicaciones de escritorio. El modelo pequeño suele tener un tamaño de alrededor de 50 Mb y requiere alrededor de 300 Mb de memoria en tiempo de ejecución. Los modelos grandes sirven para la transcripción de alta precisión en el servidor. Los modelos grandes requieren hasta 16 Gb de memoria ya que aplican algoritmos avanzados de IA. Lo ideal es ejecutarlos en algunos servidores de alta gama como i7 o el último AMD Ryzen. En AWS puede echar un vistazo a las máquinas c5a y máquinas similares en otras nubes.
La mayoría de los modelos pequeños permiten la reconfiguración dinámica del vocabulario. Los modelos grandes son estáticos y el vocabulario no se puede modificar en tiempo de ejecución."
Bueno les cuento que yo la usé a ver que pasaba:
vosk-transcriber -n vosk-model-es-0.42 -i test_es.wav -o transcription.txt
en la siguiente imagen pongo por qué va: -n

en la siguiente imagen verán el modelo grande español y su tamaño:
Modelos de voces:
https://alphacephei.com/vosk/models
https://alphacephei.com/vosk/models

Cómo desinstalar
Borre las carpetas ocultas (vealos con Ctrl + H):
.local/bin/
.local/lib/
.local/lib/

pero si tenga alguna otra aplicación de python también se le borrará. Esto me fue útil pues cuando usé la voz enorme y se colgó mi ordenador luego ya no me funcionó VOSK con la voz pequeña, pero al borrar los archivos de VOSK lo volví a instalar y funcionó bien otra vez.
Dios les bendiga
CONSULTAS:
Herramienta de reconocimiento de voz Vosk
https://alphacephei.com/vosk/
Pip install not working #66
https://github.com/alphacep/vosk-api/issues/66
https://github.com/alphacep/vosk-api/issues/66#issuecomment-1294580890
vosk-transcriber -l cn -i sample.ogg
Automatic Speech Recognition with Vosk
https://medium.com/@johnidouglasmarangon/automatic-speech-recognition-with-vosk-828569219f2b
vosk-transcriber --list-model
vosk-transcriber -n vosk-model-small-pt-0.3 -i audio_pt_br.mp3 -o transcription.txt
Gracias, ha sido de mucha utilidad
ResponderBorrar